ScanNet Indoor Scene Understanding Challenge
CVPR 2023 Workshop, Vancouver, Canada

Introduction
3D scene understanding for indoor environments is becoming an increasingly important area. Application domains such as augmented and virtual reality, computational photography, interior design, and autonomous mobile robots all require a deep understanding of 3D interior spaces, the semantics of objects that are present, and their relative configurations in 3D space.
We present the first comprehensive challenge for 3D scene understanding of entire rooms at the object instance-level with 5 tasks based on the ScanNet dataset. The ScanNet dataset is a large-scale semantically annotated dataset of 3D mesh reconstructions of interior spaces (approx. 1500 rooms and 2.5 million RGB-D frames). It is used by more than 480 research groups to develop and benchmark state-of-the-art approaches in semantic scene understanding. A key goal of this challenge is to compare state-of-the-art approaches operating on image data (including RGB-D) with approaches operating directly on 3D data (point cloud, or surface mesh representations). Additionally, we pose both object category label prediction (commonly referred to as semantic segmentation), and instance-level object recognition (object instance prediction and category label prediction). We propose five tasks that cover this space:
- 2D semantic label prediction: prediction of object category labels from 2D image representation
- 2D semantic instance prediction: prediction of object instance and category labels from 2D image representation
- 3D semantic label prediction: prediction of object category labels from 3D representation
- 3D semantic instance prediction: prediction of object instance and category labels from 3D representation
- Scene type classification: classification of entire 3D room into a scene type
Highlight - Data Efficient Challenge!
In the data efficient challenge, training is conducted on Limited Scene Reconstructions (LR) or Limited Scene Annotations (LA), for the tasks of 3D Semantic Segmentation, Instance Segmentation and Object Detection.
Highlight - ScanNet200 Challenge!
In the ScanNet200 challenge, large-vocabulary scene understanding is challenged with 200 class categories for the tasks of 3D semantic segmentation and 3D instance segmentation.
For each task, challenge participants are provided with prepared training, validation, and test datasets, and automated evaluation scripts. In addition to the public train-val-test split, benchmarking is done on a hidden test set whose raw data can be downloaded without annotations; in order to participate in the benchmark, the predictions on the hidden test set are uploaded to the evaluation server, where they are evaluated. Submission is restricted to submissions every two weeks to avoid finetuning on the test dataset. See more details at http://kaldir.vc.in.tum.de/scannet_benchmark/documentation if you would like to participate in the challenge. The evaluation server leaderboard is live at http://kaldir.vc.in.tum.de/scannet_benchmark/. See the data efficient documentation and leaderboard.

2D semantic label prediction
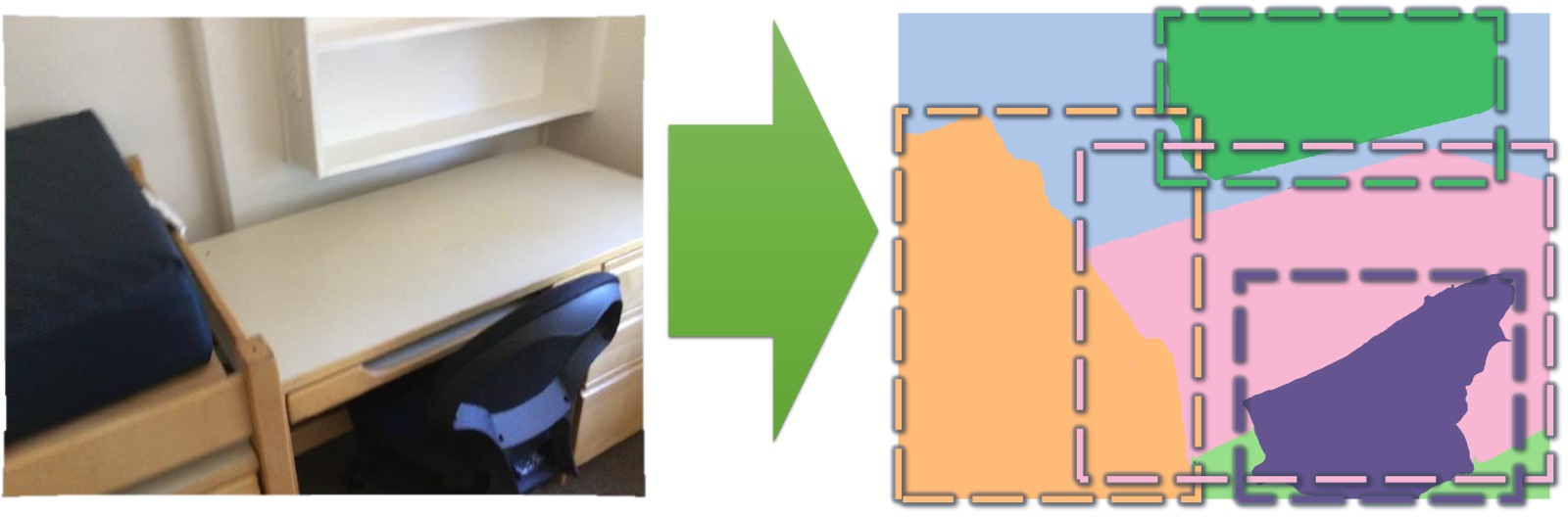
2D semantic instance prediction

3D semantic label prediction
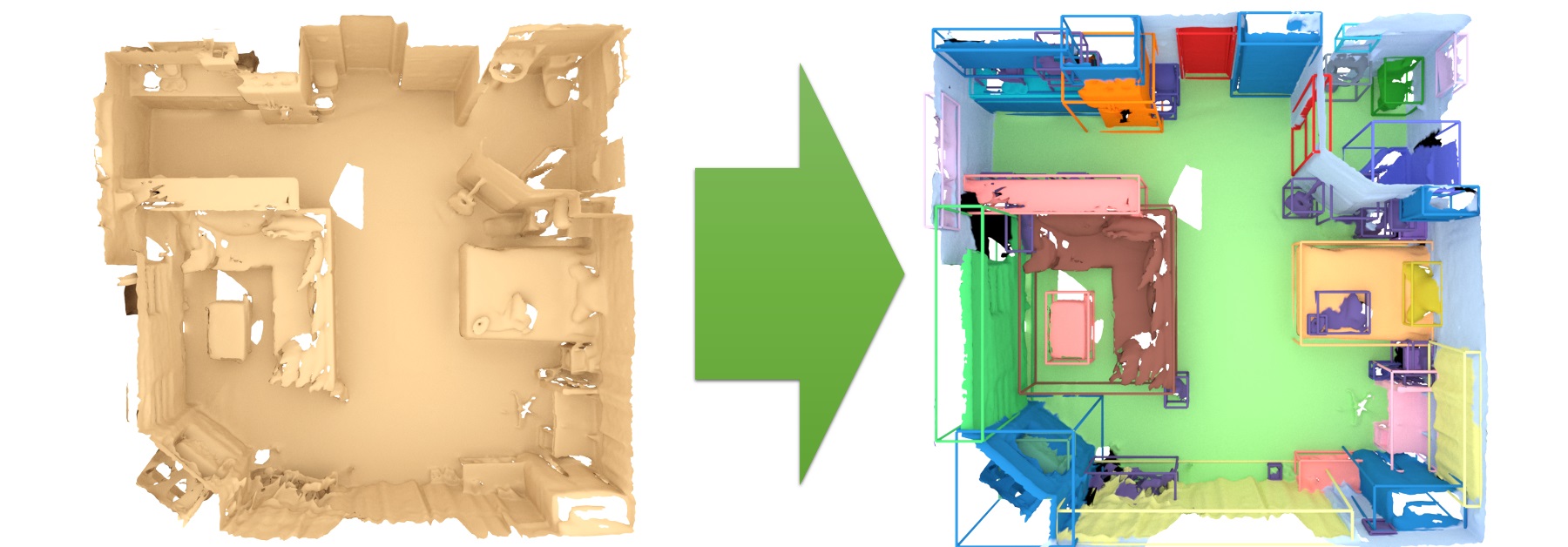
3D semantic instance prediction
Schedule
| Welcome and Introduction | 1:30pm - 1:45pm |
| Invited Talk: Peter Wonka, Data Structures for Generative Modeling of 3D shapes | 1:45pm - 2:15pm |
| Invited Talk: Leo Guibas, Neural Object and Scene Representations in the Sparse Data Regime | 2:15pm - 2:45pm |
| Winner Talk: Yukang Chen, LargeKernel3D | 2:45pm - 3:00pm |
| Winner Talk: Min Sun, Data Efficient 3D Learner | 3:00pm - 3:15pm |
| Break | 3:15pm - 3:45pm |
| Winner Talk: Khoi Nguyen, ISBNet | 3:45pm - 4:00pm |
| Invited Talk: Georgia Gkioxari, The Many Challenges and Some Solutions for 3D Object Recognition from Images | 4:00pm - 4:30pm |
| Invited Talk: Tom Funkhouser, Open Vocabulary 3D Scene Understanding Using Large Visual Language Models | 4:30pm - 5:00pm |
| Panel Discussion and Conclusion | 5:00pm - 5:30pm |
Invited Speakers

Leonidas Guibas is the Paul Pigott Professor of Computer Science (and by courtesy), Electrical Engineering at Stanford University, where he heads the Geometric Computation group. Dr. Guibas obtained his Ph.D. from Stanford University under the supervision of Donald Knuth. His main subsequent employers were Xerox PARC, DEC/SRC, MIT, and Stanford. He is a member and past acting director of the Stanford Artificial Intelligence Laboratory and a member of the Computer Graphics Laboratory, the Institute for Computational and Mathematical Engineering (iCME), and the Bio-X program. Dr. Guibas has been elected to the US National Academy of Engineering, the US National Academy of Sciences, the American Academy of Arts and Sciences and is an ACM Fellow, an IEEE Fellow, and winner of the ACM Allen Newell Award and the ICCV Helmholtz prize.

Georgia Gkioxari is an Assistant Professor of Computing + Mathematical Sciences at Caltech. From 2016 to 2022, she was a research scientist at FAIR. She received her PhD from UC Berkeley, advised by Jitendra Malik. She received her bachelors in ECE at NTUA in Athens, Greece. Professor Gkioxari's work has been recognized by various awards, including the PAMI Young Researcher Award (2021), as well as the PAMI Mark Everingham Award (2021) for the Detectron Library Suite. She has also been named one of 30 influential women advancing AI in 2019 by ReWork, and nominated for the Women in AI Awards in 2020 by VentureBeat.

Peter Wonka is a Full Professor in Computer Science at King Abdullah University of Science and Technology (KAUST) and Interim Director of the Visual Computing Center (VCC). Peter Wonka received his doctorate from the Technical University of Vienna in computer science. Additionally, he received a Masters of Science in Urban Planning from the same institution. After his PhD, Dr. Wonka worked as a postdoctoral researcher at the Georgia Institute of Technology and as faculty at Arizona State University. His research publications tackle various topics in computer vision, computer graphics, and machine learning. The current research focus is on deep learning, generative models, and 3D shape analysis and reconstruction..

Tom Funkhouser is a principal research scientist at Google and a Professor Emeritus at Princeton University. His research interests include 3D computer vision and computer graphics, with a current focus on 3D scene understanding. He is an ACM Fellow, a member of the ACM SIGGRAPH Academy, and a recipient of the ACM SIGGRAPH Achievement Award, Sloan Foundation Fellowship, NSF Career Award, two Excellence in Teaching Awards, and several best paper awards.
Organizers

Technical University of Munich

Simon Fraser University

Simon Fraser University

Technical University of Munich
Acknowledgments
Thanks to visualdialog.org for the webpage format.