ScanNet Indoor Scene Understanding Challenge
CVPR 2022 Workshop, New Orleans, LA
June 19, 2022, Afternoon, 201-202

Introduction
3D scene understanding for indoor environments is becoming an increasingly important area. Application domains such as augmented and virtual reality, computational photography, interior design, and autonomous mobile robots all require a deep understanding of 3D interior spaces, the semantics of objects that are present, and their relative configurations in 3D space.
We present the first comprehensive challenge for 3D scene understanding of entire rooms at the object instance-level with 5 tasks based on the ScanNet dataset. The ScanNet dataset is a large-scale semantically annotated dataset of 3D mesh reconstructions of interior spaces (approx. 1500 rooms and 2.5 million RGB-D frames). It is used by more than 480 research groups to develop and benchmark state-of-the-art approaches in semantic scene understanding. A key goal of this challenge is to compare state-of-the-art approaches operating on image data (including RGB-D) with approaches operating directly on 3D data (point cloud, or surface mesh representations). Additionally, we pose both object category label prediction (commonly referred to as semantic segmentation), and instance-level object recognition (object instance prediction and category label prediction). We propose five tasks that cover this space:
- 2D semantic label prediction: prediction of object category labels from 2D image representation
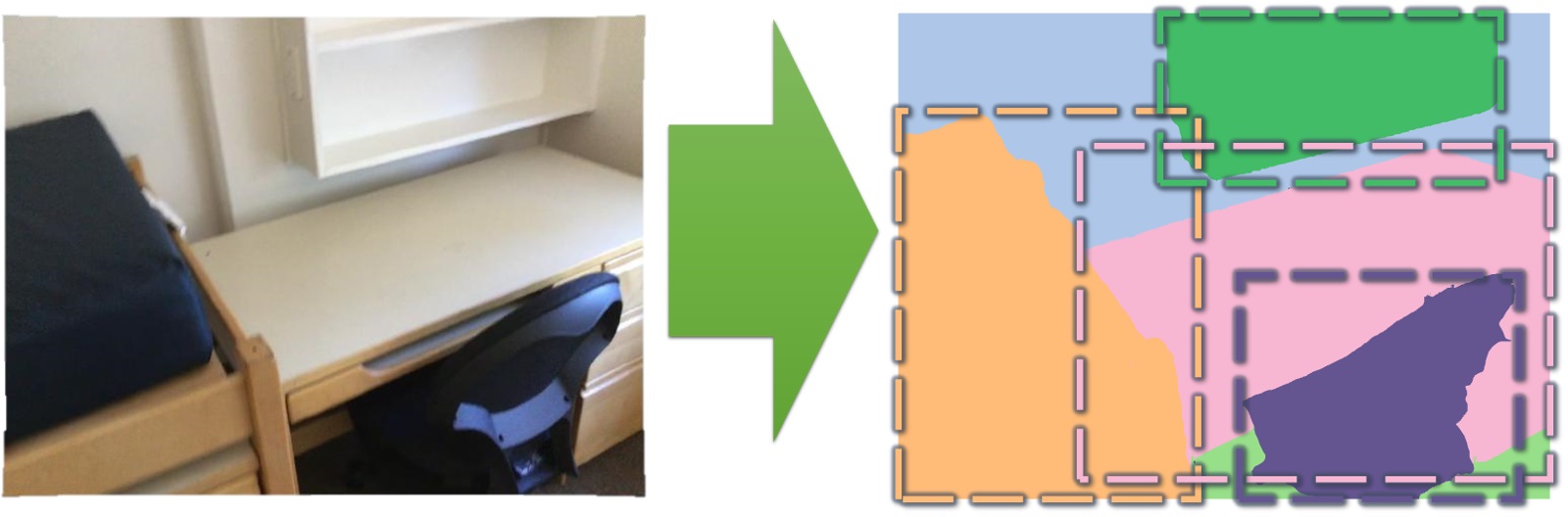
- 2D semantic instance prediction: prediction of object instance and category labels from 2D image representation
- 3D semantic label prediction: prediction of object category labels from 3D representation
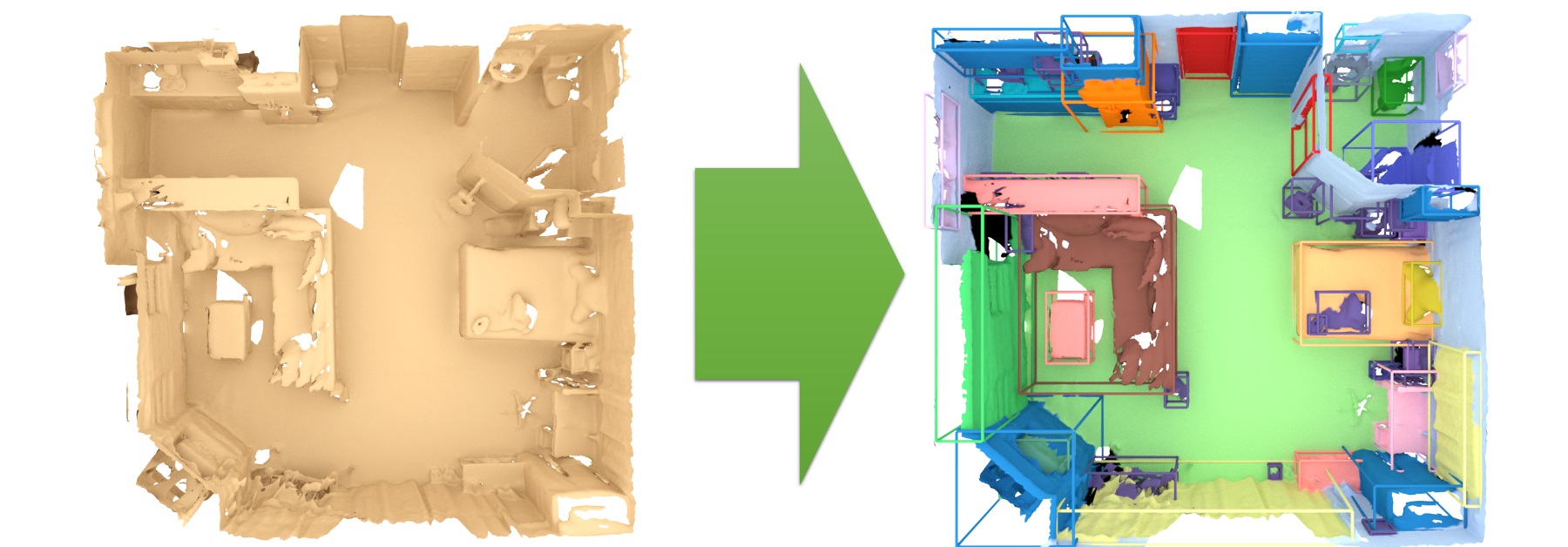
- 3D semantic instance prediction: prediction of object instance and category labels from 3D representation
- Scene type classification: classification of entire 3D room into a scene type
Highlight - Data Efficient Challenge!
In the data efficient challenge, training is conducted on Limited Scene Reconstructions (LR) or Limited Scene Annotations (LA), for the tasks of 3D Semantic Segmentation, Instance Segmentation and Object Detection.
For each task, challenge participants are provided with prepared training, validation, and test datasets, and automated evaluation scripts. In addition to the public train-val-test split, benchmarking is done on a hidden test set whose raw data can be downloaded without annotations; in order to participate in the benchmark, the predictions on the hidden test set are uploaded to the evaluation server, where they are evaluated. Submission is restricted to submissions every two weeks to avoid finetuning on the test dataset. See more details at http://kaldir.vc.in.tum.de/scannet_benchmark/documentation if you would like to participate in the challenge. The evaluation server leaderboard is live at http://kaldir.vc.in.tum.de/scannet_benchmark/. See the new data efficient documentation and leaderboard!.

2D semantic label prediction
2D semantic instance prediction

3D semantic label prediction
3D semantic instance prediction
Schedule (All times in CDT)
| Welcome and Introduction | 12:50pm - 1:00pm |
| Invited Talk: Ingredients for Mapping the Metaverse (Peter Kontschieder) | 1:00pm - 1:50pm |
| Winner Talk: One Thing One Click (Zhengzhe Liu) | 1:50pm - 2:05pm |
| Winner Talk: Mix3D (Alexey Nekrasov) | 2:05pm - 2:20pm |
| Winner Talk: SoftGroup (Thang Vu) | 2:20pm - 2:35pm |
| Break | 2:35pm - 3:00pm |
| Invited Talk: Rethinking 3D Segmentation (Francis Engelmann) | 3:00pm - 3:50pm |
| Invited Talk: Towards Data-Efficient and Continual Learning for 3D Scene Understanding (Gim Hee Lee) | 4:00pm - 4:50pm |
| Panel Discussion and Conclusion | 5:00pm - 5:45pm |
Invited Speakers

Gim Hee Lee is an Associate Professor at the Department of Computer Science at the National University of Singapore (NUS), where he heads the Computer Vision and Robotic Perception (CVRP) Laboratory. He was a researcher at Mitsubishi Electric Research Laboratories (MERL), USA. Prior to MERL, he did his PhD in Computer Science at ETH Zurich, Switzerland. He received his B.Eng and M.Eng degrees from the Department of Mechanical Engineering at NUS. His research interests are in Computer Vision, Machine Learning, and Robotics.

Francis Engelmann is a post-doctoral research fellow at the ETH AI Center, at the department of Computer Science. His research lies at the intersection of computer vision and deep learning with a special focus on large-scale 3D scene understanding, including semantic instance segmentation, object detection and reconstruction. Before joining ETH Zurich, he received his Ph.D. from RWTH Aachen University and spent some time at Google Munich and Zurich, as well as Apple in California.

Peter Kontschieder is a research scientist manager at Meta. He received his MSc and PhD degrees from the Graz University of Technology, Graz, Austria, in 2008 and 2013, respectively. From 2013-2016, he was a postdoctoral researcher with the Machine Intelligence and Perception Group, Microsoft Research in Cambridge, United Kingdom. In 2016, he joined Mapillary and founded Mapillary Research – Mapillary’s Research Lab focusing on basic research in computer vision and machine learning. With the acquisition of Mapillary in 2020, he became a research scientist manager with Facebook. He received the Marr Prize in 2015 for his contribution of Deep Neural Decision Forests, joining deep learning with decision forests.
Organizers

Technical University of Munich

Simon Fraser University

Simon Fraser University

Technical University of Munich
Acknowledgments
Thanks to visualdialog.org for the webpage format.