3rd ScanNet Indoor Scene Understanding Challenge
CVPR 2021 Workshop
June 20, 2021
Join Us Here: Live Stream

Introduction
3D scene understanding for indoor environments is becoming an increasingly important area. Application domains such as augmented and virtual reality, computational photography, interior design, and autonomous mobile robots all require a deep understanding of 3D interior spaces, the semantics of objects that are present, and their relative configurations in 3D space.
We present the first comprehensive challenge for 3D scene understanding of entire rooms at the object instance-level with 5 tasks based on the ScanNet dataset. The ScanNet dataset is a large-scale semantically annotated dataset of 3D mesh reconstructions of interior spaces (approx. 1500 rooms and 2.5 million RGB-D frames). It is used by more than 480 research groups to develop and benchmark state-of-the-art approaches in semantic scene understanding. A key goal of this challenge is to compare state-of-the-art approaches operating on image data (including RGB-D) with approaches operating directly on 3D data (point cloud, or surface mesh representations). Additionally, we pose both object category label prediction (commonly referred to as semantic segmentation), and instance-level object recognition (object instance prediction and category label prediction). We propose five tasks that cover this space:
- 2D semantic label prediction: prediction of object category labels from 2D image representation
- 2D semantic instance prediction: prediction of object instance and category labels from 2D image representation
- 3D semantic label prediction: prediction of object category labels from 3D representation
- 3D semantic instance prediction: prediction of object instance and category labels from 3D representation
- Scene type classification: classification of entire 3D room into a scene type
New This Year - Data Efficient Challenge!
In the data efficient challenge, training is conducted on Limited Scene Reconstructions (LR) or Limited Scene Annotations (LA), for the tasks of 3D Semantic Segmentation, Instance Segmentation and Object Detection.
For each task, challenge participants are provided with prepared training, validation, and test datasets, and automated evaluation scripts. In addition to the public train-val-test split, benchmarking is done on a hidden test set whose raw data can be downloaded without annotations; in order to participate in the benchmark, the predictions on the hidden test set are uploaded to the evaluation server, where they are evaluated. Submission is restricted to submissions every two weeks to avoid finetuning on the test dataset. See more details at http://kaldir.vc.in.tum.de/scannet_benchmark/documentation if you would like to participate in the challenge. The evaluation server leaderboard is live at http://kaldir.vc.in.tum.de/scannet_benchmark/. See the new data efficient documentation and leaderboard!.

2D semantic label prediction
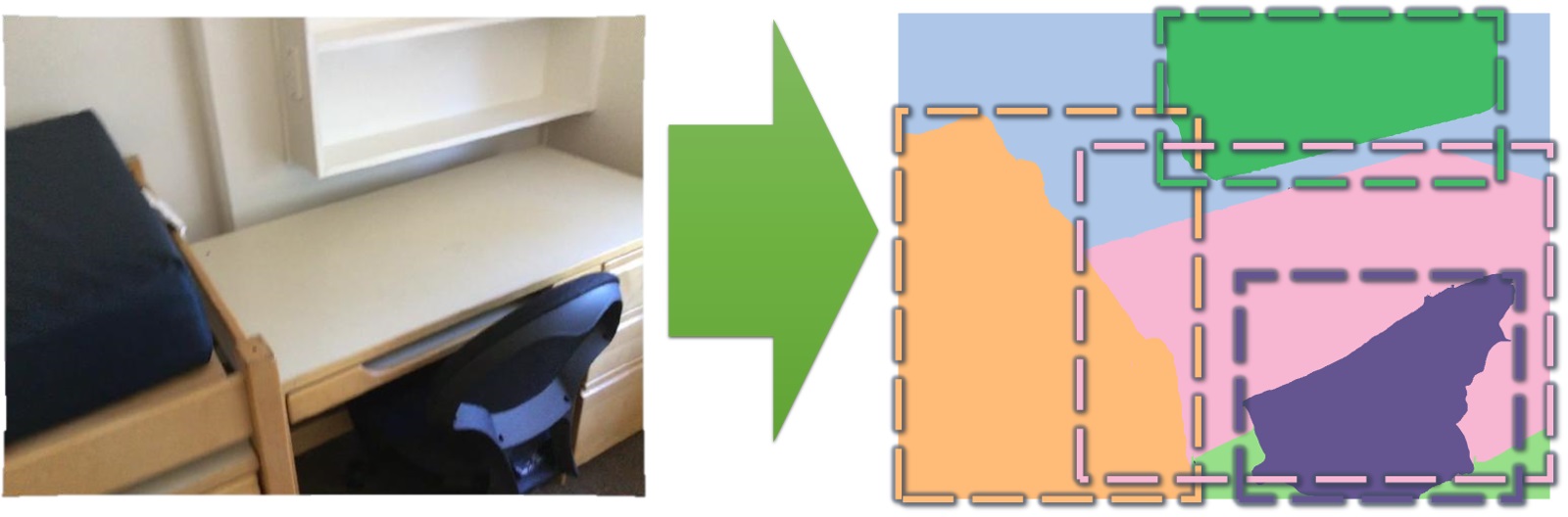
2D semantic instance prediction

3D semantic label prediction
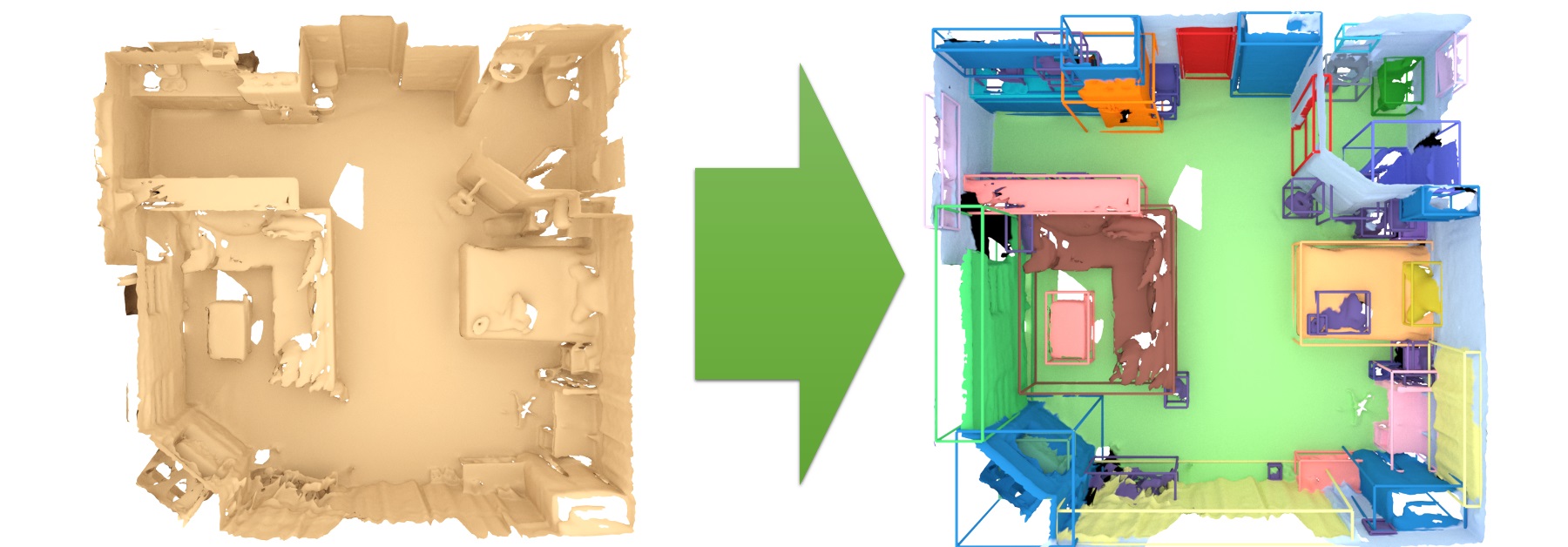
3D semantic instance prediction
Schedule
| PDT | CEST | |
| Welcome and Introduction | 8:50am - 9:00am | 5:50pm - 6:00pm |
| Neural Surface Representations (Niloy Mitra) | 9:00am - 10:00am | 6:00pm - 7:00pm |
| Winner Talk: Point Cloud Instance Segmentation using Probabilistic Embeddings (Biao Zhang) | 10:00am - 10:10am | 7:00pm - 7:10pm |
| Winner Talk: BPNet (Wenbo Hu) | 10:10am - 10:20am | 7:10pm - 7:20pm |
| Winner Talk: Virtual MVFusion (Abhijit Kundu) | 10:20am - 10:30am | 7:20pm - 7:30pm |
| Offboard 3D Object Detection From Point Cloud Sequences (Charles Qi) | 10:30am - 11:00am | 7:30pm - 8:00pm |
| Towards Gigapixel 3D Imaging (Lu Fang) | 11:00am - 11:30am | 8:00pm - 8:30pm |
| Transfer3D: Learning Transferrable Representations of 3D Scenes (Saining Xie) | 11:30am - 12:00pm | 8:30pm - 9:00pm |
| Panel Discussion and Conclusion | 12:00pm - 12:30pm | 9:00pm - 9:30pm |
Invited Speakers

Niloy Mitra is a Professor of Geometry Processing in the Department of Computer Science, University College London (UCL). He received his MS and PhD in Electrical Engineering from Stanford University under the guidance of Leonidas Guibas and Marc Levoy, and was a postdoctoral scholar with Helmut Pottmann at Technical University Vienna. His research interests include shape analysis, computational design and fabrication, and geometry processing. Niloy received the 2013 ACM Siggraph Significant New Researcher Award for "his outstanding work in discovery and use of structure and function in 3D objects" (UCL press release), the BCS Roger Needham award (BCS press release) in 2015, and the Eurographics Outstanding Technical Contributions Award in 2019. He received the ERC Starting Grant on SmartGeometry in 2013. His work has twice been featured as research highlights in the Communications of the ACM, twice been selected by ACM Siggraph/Siggraph Asia (both in 2017) for press release as research highlight.

Charles Qi is a research scientist at Waymo LLC. Previously, he was a postdoctoral researcher at Facebook AI Research (FAIR) and received his Ph.D. from Stanford University (Stanford AI Lab and Geometric Computation Group), advised by Professor Leonidas J. Guibas. Prior to Stanford, he received his B.Eng. from Tsinghua University. His research focuses on deep learning, computer vision and 3D. He has developed novel deep learning architectures for 3D data (point clouds, volumetric grids and multi-view images) that have wide applications in 3D object classification, object part segmentation, semantic scene parsing, scene flow estimation and 3D reconstruction; such deep architectures have been well adopted by both academic and industrial groups across the world.

Lu Fang is an Associate Professor at Tsinghua University. She received her Ph.D from the Hong Kong University of Science and Technology in 2011, and her B.E. from Univ. of Science and Technology of China in 2007, respectively. Prof. Fang's research interests include computational imaging and 3D vision. Prof. Fang's research has been recognized by the NSFC Excellent Young Scholar Award, Multimedia Rising Star Award in ICME 2019, Best Student Paper Award in ICME 2017, and more. Prof. Fang is an currently IEEE Senior Member, and serving as an Associate Editor for IEEE TMM and TCSVT.

Saining Xie is a research scientist at Facebook AI Research (FAIR). He received a PhD in computer science from the University of California San Diego in 2018, advised by Zhuowen Tu. Prior to that, he received his B.S. from Shanghai Jiao Tong University in 2013. He has broad research interests in computer vision and deep learning, with a focus on representation learning for visual recognition in both 2D and 3D. He is a recipient of the Google Ph.D. fellowship in 2017 and the Marr Prize Honorable Mention award at ICCV 2015.
Organizers

Technical University of Munich

Simon Fraser University

Simon Fraser University

Technical University of Munich
Acknowledgments
Thanks to visualdialog.org for the webpage format.