ScanNet Indoor Scene Understanding Challenge
CVPR 2019 Workshop, Long Beach, CA

Introduction
3D scene understanding for indoor environments is becoming an increasingly important area. Application domains such as augmented and virtual reality, computational photography, interior design, and autonomous mobile robots all require a deep understanding of 3D interior spaces, the semantics of objects that are present, and their relative configurations in 3D space.
We present the first comprehensive challenge for 3D scene understanding of entire rooms at the object instance-level with 5 tasks based on the ScanNet dataset. The ScanNet dataset is a large-scale semantically annotated dataset of 3D mesh reconstructions of interior spaces (approx. 1500 rooms and 2.5 million RGB-D frames). It is used by more than 480 research groups to develop and benchmark state-of-the-art approaches in semantic scene understanding. A key goal of this challenge is to compare state-of-the-art approaches operating on image data (including RGB-D) with approaches operating directly on 3D data (point cloud, or surface mesh representations). Additionally, we pose both object category label prediction (commonly referred to as semantic segmentation), and instance-level object recognition (object instance prediction and category label prediction). We propose five tasks that cover this space:
- 2D semantic label prediction: prediction of object category labels from 2D image representation
- 2D semantic instance prediction: prediction of object instance and category labels from 2D image representation
- 3D semantic label prediction: prediction of object category labels from 3D representation
- 3D semantic instance prediction: prediction of object instance and category labels from 3D representation
- Scene type classification: classification of entire 3D room into a scene type
For each task, challenge participants are provided with prepared training, validation, and test datasets, and automated evaluation scripts. In addition to the public train-val-test split, benchmarking is done on a hidden test set whose raw data can be downloaded without annotations; in order to participate in the benchmark, the predictions on the hidden test set are uploaded to the evaluation server, where they are evaluated. Submission is restricted to submissions every two weeks to avoid finetuning on the test dataset. See more details at http://kaldir.vc.in.tum.de/scannet_benchmark/documentation if you would like to participate in the challenge. The evaluation server leaderboard is live at http://kaldir.vc.in.tum.de/scannet_benchmark/.

2D semantic label prediction
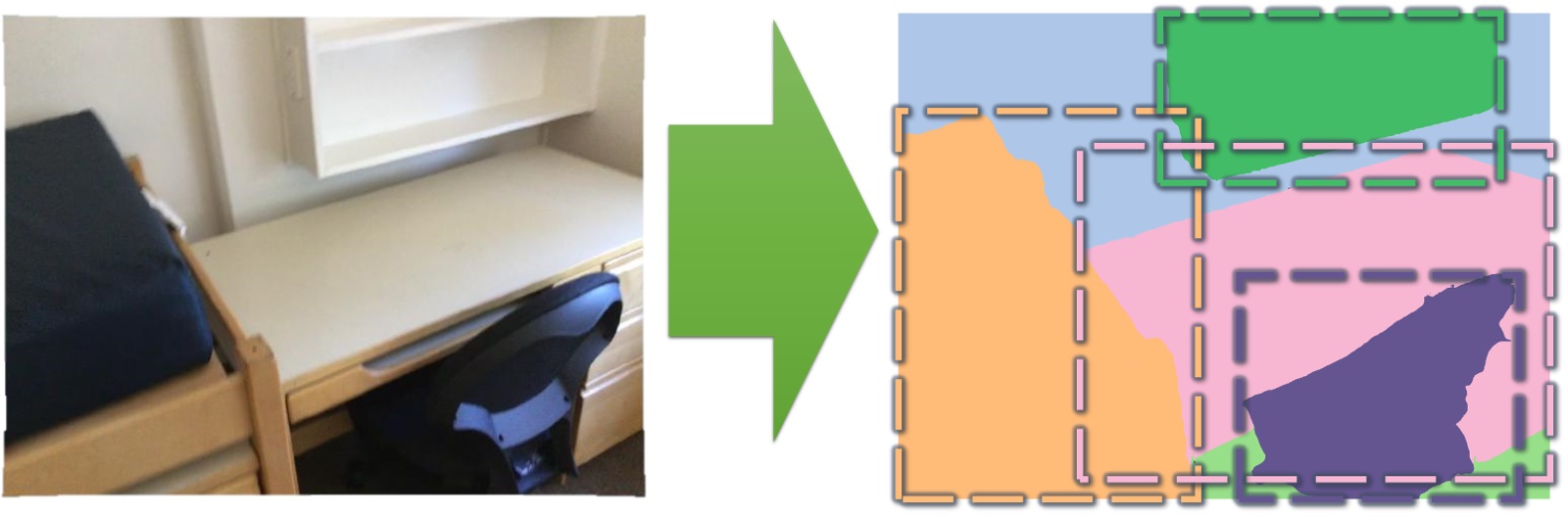
2D semantic instance prediction

3D semantic label prediction
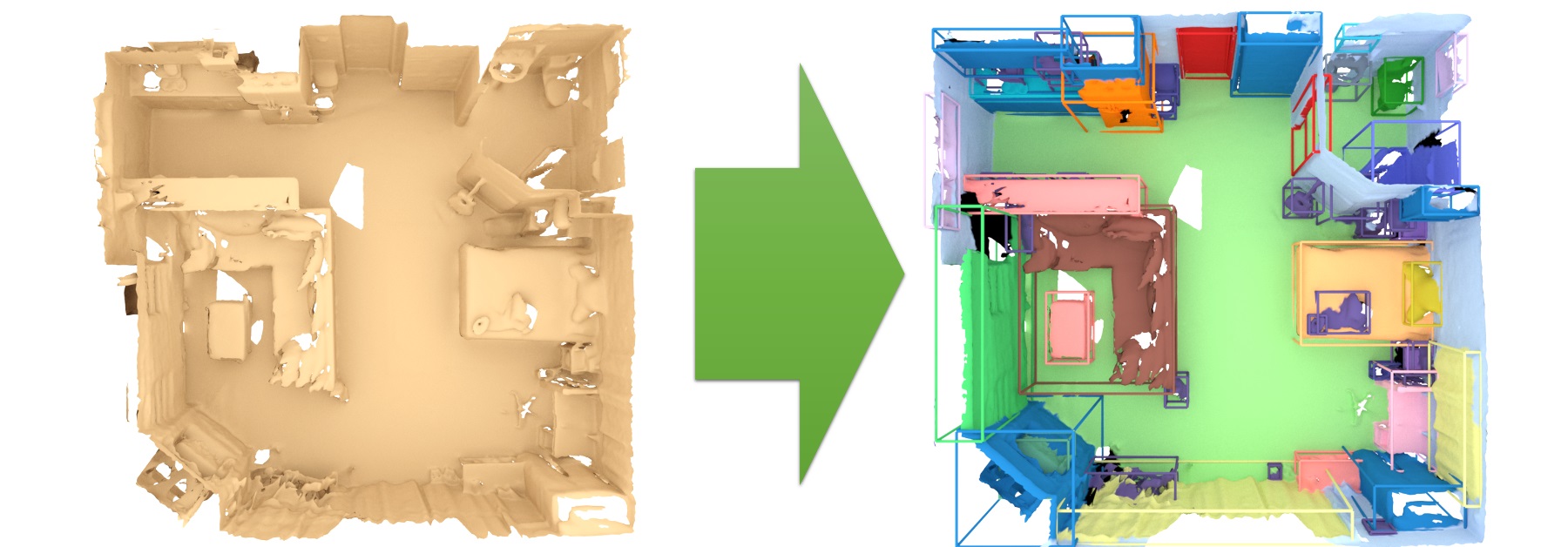
3D semantic instance prediction
Important Dates
| Poster Submission Deadline | May 15 2019 |
| Notification to Authors | May 20 2019 |
| Workshop Date | June 16 2019 |
Posters
To submit a poster to the workshop, please email the poster as .pdf file to scannet@googlegroups.com.
Schedule
| Welcome and Introduction | 1:45pm - 2:00pm |
| Invited Talk 1: Jitendra Malik, Seeing while moving and moving while seeing in a 3D world | 2:00pm - 2:30pm |
| Winner Talk 1 (MinkowskiNet / Chris Choy) | 2:30pm - 2:45pm |
| Winner Talk 2 (joint point-based / Hung-Yueh Chiang) | 2:45pm - 3:00pm |
| Winner Talk 3 (MTML / Jean Lahoud) | 3:00pm - 3:15pm |
| Winner Talk 4 (PanopticFusion / Gaku Narita) | 3:15pm - 3:30pm |
| Break and poster session | 3:30pm - 4:00pm |
| Invited Talk 2: Leo Guibas, Deep Learning on 3D Point Clouds | 4:00pm - 4:30pm |
| Invited Talk 3: Denver Dash, Deep 3D: The New Frontier of Computer Vision | 4:30pm - 5:00pm |
| Panel Discussion and Conclusion | 5:00pm - 5:30pm |
Invited Speakers

Leonidas J. Guibas heads the Geometric Computation group in the Computer Science Department of Stanford University. He is acting director of the Artificial Intelligence Laboratory and member of the Computer Graphics Laboratory, the Institute for Computational and Mathematical Engineering (iCME) and the Bio-X program. His research centers on algorithms for sensing, modeling, reasoning, rendering, and acting on the physical world. Professor Guibas' interests span computational geometry, geometric modeling, computer graphics, computer vision, sensor networks, robotics, and discrete algorithms --- all areas in which he has published and lectured extensively.

Jitendra Malik received the B.Tech degree in Electrical Engineering from Indian Institute of Technology, Kanpur in 1980 and the PhD degree in Computer Science from Stanford University in 1985. In January 1986, he joined the university of California at Berkeley, where he is currently the Arthur J. Chick Professor in the Department of Electrical Engineering and Computer Sciences. He is also on the faculty of the department of Bioengineering, and the Cognitive Science and Vision Science groups. During 2002-2004 he served as the Chair of the Computer Science Division, and as the Department Chair of EECS during 2004-2006 as well as 2016-2017. Since January 2018, he is also Research Director and Site Lead of Facebook AI Research in Menlo Park.

Denver Dash is the Director of Machine Learning at Occipital, where he focuses on combining machine learning with geometric vision to solve problems in 3d perception. In 2014 he became a Principal Engineer and approximately employee number 80 at Magic Leap, where he grew the Machine Learning team from scratch. In 2016 he became the Director of Gesture Recognition and led the development of the hand tracking system that was put into production for Magic Leap One. Prior to Magic Leap, Denver was a Sr. Research Scientist at the Intel Research lab at Carnegie Mellon University, where he served as adjunct faculty at the Robotics Institute, developing novel multi-modal approaches for computer vision and generative models for causal reasoning.
Organizers

Technical University of Munich

Eloquent Labs, Simon Fraser University

Simon Fraser University, Facebook AI Research

Technical University of Munich
Acknowledgments
Thanks to visualdialog.org for the webpage format.